
エンジニアがより賢いモデルを拒否したとき:AI推論戦争でOpenAI�は“銃”を変えた

AI推論市場は深いパラダイムシフトを迎えています——今、開発者が支払う価値のある主な変数は「知能」ではなく「速度」なのです。この嗜好の逆転は、長らく周縁にあったチップ企業Cerebrasをスポットライトの中央に押し上げ、また、OpenAIがIPOを控えるウェハー級チップメーカーに数百億ドルで巨額な賭けを行う要因ともなっています。
業界研究機関SemiAnalysisの詳細なレポートによれば、OpenAIはCerebrasと総規模750MWの推論能力提供に関するマスター契約を結んでおり、さらに2GWまでの拡張が可能、未履行義務部分で246億ドルに及ぶとされています。
この取引のコアロジックは次の通りです:OpenAI傘下のGPT-5.3-Codex-SparkモデルはCerebrasハードウェア上で1ユーザー毎秒2000トークン生成を実現し、HBMベースのGPUクラスタより遥かに快適なインタラクション体験を提供します。同時にCerebrasはIPO間近で、その運命はOpenAIと深く結びついています。
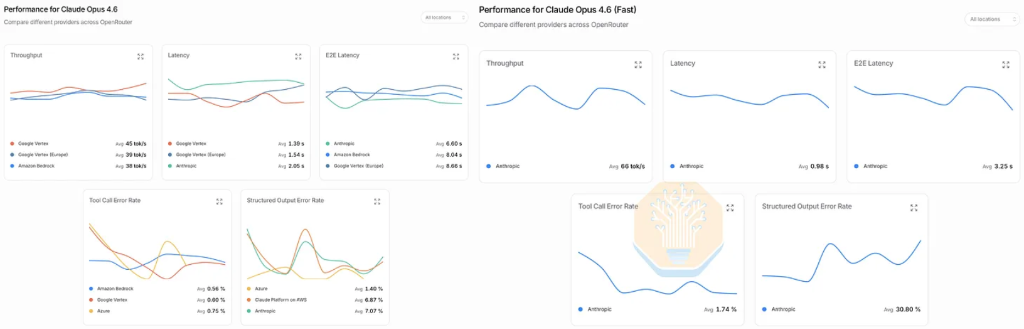
この速度革命の市場シグナルは、すでにかなり明確になっています。SemiAnalysisは、自チームのAI支出(年率最大1000万ドル)の80%がAnthropicのOpus 4.6高速モードに集中している事実を開示——このモードは2.5倍のインタラクション速度と引き換えに6倍の価格を正当化していました。さらに印象的なのは、Opus 4.7がリリースされた際に、エンジニアたちの多くがアップグレードを拒み、理由は単に新バージョンが高速モードをサポートしないこと——これはSemiAnalysisチームが初めて、最先端の知能より、より高速なトークン生成を積極的に選んだ瞬間でした。
速度プレミアム:開発者は財布で投票する
推論市場の競争構造は新たな軸上で再編されています。
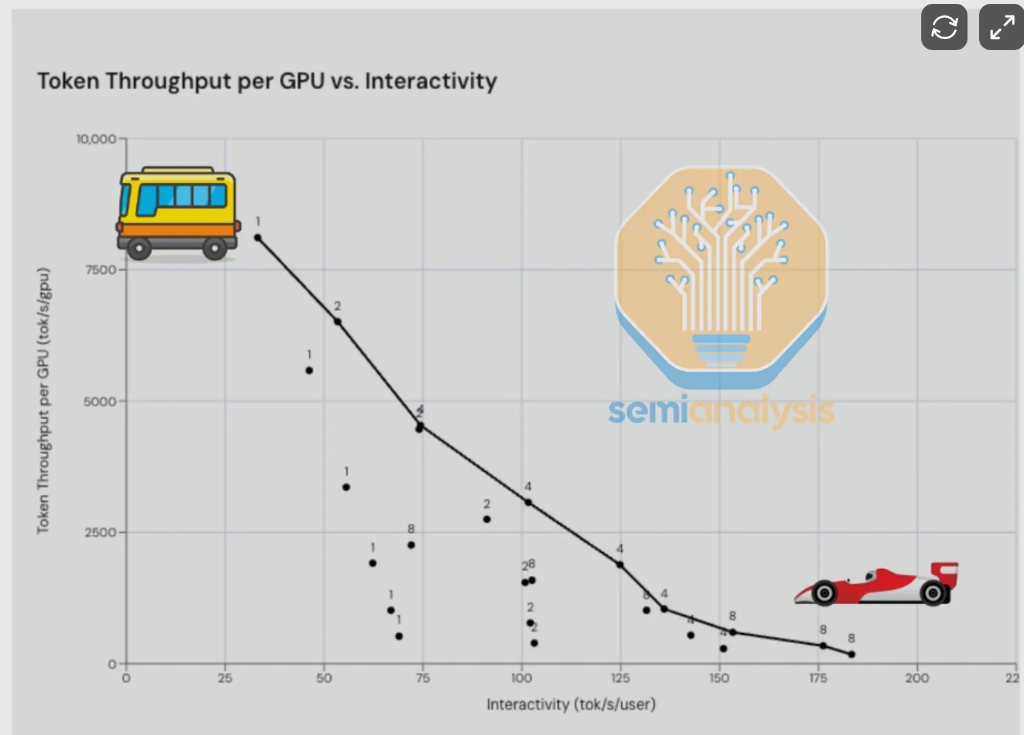
NVIDIAのCEO Jensen Huangが今年のGTCカンファレンスで繰り返し強調したように、スループット(GPUごとの秒間トークン数)とインタラクティビティ(ユーザーごとの秒間トークン数)は推論における本質的なトレードオフです——前者はバッチ処理向け、後者はユーザー体験を決定する。SemiAnalysisはこれを「バスとフェラーリ」の選択にたとえました——ゆっくり多くのユーザーを扱うか、素早く個々のユーザーを扱うかです。
市場の嗜好は消費行動によって検証されています。Opus 4.6高速モードは6倍の価格で約2.5倍のインタラクション速度を実現し、一時Anthropicの最も利益率が高いプロダクトSKUとなり、同社の今年のARR爆発的成長の主要ドライバーとなりました。しかし、SemiAnalysisとOpenRouterの協力で収集されたデータによると、最近このモードはパフォーマンス劣化が見られます——スタンダードOpus 4.6のインタラクション速度は約40tpsで安定、高速モードは100tps超だったものが直近70tpsほどに低下し、実効的な加速倍率は2.5倍から1.75倍程度に縮小しました。
OpenAIもAnthropicもこの需要の階層分化を認識し、高速モード、優先モード、バルク価格など様々なプロダクト形態で市場全体をカバーしつつ利益最大化のポートフォリオを模索しています。
ウェハー級チップ:ハイリスク・ハイリターンな技術的論理
Cerebrasの主な賭けは、光リソグラフィ単回露光の物理的リミットを突破し、一枚のウェハーをそのまま一つのチップとして使うことにあります。
第3世代製品WSE-3はTSMC N5プロセスに基づき、1ウェハー上に44GB SRAMを統合し、21PB/sというメモリ帯域幅を提供します——これはHBMの数千倍規模です。このアーキテクチャの本質は、非常に高いメモリ帯域幅によってきわめて低いメモリアクセス遅延を実現し、小規模バッチ・低演算強度のデコードシナリオでその理論性能を存分に発揮できる点であり、HBMベースGPUは同様のシナリオ下でしばしば「計算渇望」状態となります。
しかしこのアーキテクチャには明確な計算密度コストもあります。SemiAnalysisは、WSE-3の密度FP16演算性能は実際には15.625 PFLOPSに過ぎず、これはCerebras公式の125 PFLOPSから8倍の差があり、その差は8:1非構造的スパースネスの仮定に由来すると指摘しています。SemiAnalysisはこれを「Feldman公式」と呼び、NVIDIAの「Jensen数学」と並列で扱っていますが、前者の方が一段と先鋭だとみています。
システムコスト面で、SemiAnalysisの試算ではCS-3サーバ一台の物材コスト(KVSS CPUノード含む)は約45万ドルで、そのうちTSMCウェハー原価は2万ドル程度と遥かに安いです。高価なカスタム電源(Vicor製)、液冷システム、各バッチ製造ウェハーのカスタムマスクコストなど、総合的にコスト構造を押し上げています。

アーキテクチャの弱点:ネットワーク帯域幅のジオメトリックな課題
WSE-3の最も顕著な弱点は、きわめて限定的なチップ外帯域幅です。
WSE-3は1枚あたり150GB/s(1.2Tb/s)のチップ外帯域しか持たず、NVIDIA Blackwell NVLink5単一GPUの900GB/sスケールアウト帯域の6分の1です。これは設計ミスではなく、ウェハー級アーキテクチャの本質的な制約です——SemiAnalysisはこれを「アイランド問題」と名付けています。
課題の根源はウェハーの均一ステップ露光メカニズムにあります。WSE-3は84個同一の露光ユニット(die)で構成され、各ユニットは完全同一でないとdie間のオンチップ2Dメッシュが正常動作しません。つまりSerDes PHYをウェハー端部にまとめて配置することはできず、I/O帯域を上げるには各ユニットでPHYスペースを確保する必要がありますが、ウェハー内部のPHYは外部接続できず大量の「スタックドシリコン」となります。加えて、PHYモジュールはオンチップメッシュに「空洞」をつくり、データルーティングの遅延を増やし、アーキテクチャの強みを削ぐことなります。
この帯域ボトルネックは、Cerebrasによる大規模モデルサービス能力に直結する制約です。パラメータが1兆超、コンテキストウィンドウが100万トークンオーバーの現代的AIワークロードには、Cerebrasはパイプライン並列戦略でモデルを層ごと複数ウェハーへ配置、ウェハー間では活性値だけを転送します。しかしモデル規模が拡大すると必要ウェハー枚数が線形増加し、ウェハー間通信毎の一定遅延も蓄積し、速度アドバンテージが侵食されていきます。
SRAM拡張はほぼ限界:ロードマップの懸念材料
Cerebrasのもう一つの構造的課題は、SRAM密度拡張の物理的限界です。
WSE-1(TSMC 16nm, 18GB SRAM)からWSE-2(7nm, 40GB)でSRAM容量は2.2倍に増えています。しかしWSE-3は7nm→5nmへ進化しつつもSRAMは40GB→44GBでわずか10%増、ロジックトランジスタは約50%増です。SemiAnalysisによれば、5nm以降のTSMCプロセス(N3E対N5)でSRAMセル面積はほぼ縮小せず、N2やその先も同様——SRAM拡張は実質的にストップ状態なのです。
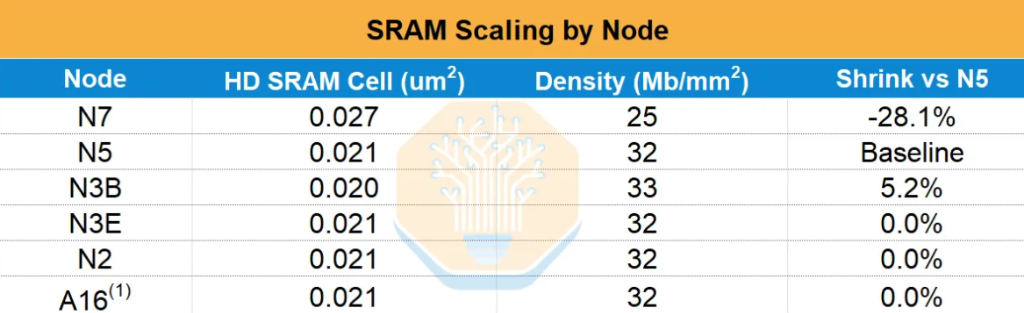
つまり、Cerebrasが今後SRAM容量を増やす唯一の道は、固定ウェハー面積内で計算エリアを減らし格納エリアを増やす——厳しいゼロサムトレードオフしかありません。次世代CS-4システムもN5ベースのWSE-3を継続し、消費電力引き上げによるクロックと演算性能向上のみ、SRAM容量は据え置きとなります。
一方、NVIDIAはGroq買収後、混合ボンディング技術でSRAMチップをZ軸方向に積層(LP40ロードマップ)することで平面拡張の制限を回避可能です。Cerebrasも同様に、DRAMウェハーや光子インターコネクトウェハーの混合積層を模索していますが、SemiAnalysisは技術的成立性やタイムラインに慎重な見方で、ウェハー級混合ボンディングは通常チップより遥かに高い熱機械ストレスやボンディング波課題に直面するとしています。
OpenAI取引:単一顧客の両刃の剣
CerebrasとOpenAIの関係は、単なるサプライヤーと顧客の枠をはるかに超えています。
SemiAnalysisが引用したS-1申請によれば、2025年12月に両者はマスターリレーション契約(MRA)を締結、OpenAIは2026~2028年にかけて総750MW AI推論能力の分割購入を約し、各バッチ契約は3~4年、最長5年まで延長可能、また追加で1.25GW購入オプションも保有。2025年末時点でCerebrasの未履行義務は246億ドルとなっています。
資本構造上、OpenAIはCerebrasへ10億ドル担保付き運転資金ローン(年利6%、算力納入返済なら利息免除)を供給し、N種(議決権なし)普通株3344.5万株ワラント(権利行使価格ほぼゼロ)を保有し、完全希薄化後でCerebras株のおよそ12%を保有する可能性もあります。万一MRAがOpenAI以外要因で終了した場合、Cerebrasは直ちに全ローン残高および利息を返済しなければならず、OpenAIは管理口座資金の使用を直接制御する権利があります。
こうした構造上、Cerebrasの成長見通しは単一顧客への強い依存状態となります。SemiAnalysisは、Cerebrasの今後数年の収益は明確なターニングポイントを迎え、OpenAIが成長の主ドライバーですが、同時に実行リスクも集中——2028年までにCerebrasが納入しなければならないサーバー数は、過去累計出荷を桁違いに超え、データセンター容量着地のタイミングが最大の不確定要素と見られています。
速度と知能のトレード:このディールはいくらの価値があるか
OpenAIがCerebras上で動かす主力GPT-5.3-Codex-Sparkは、真のGPT-5.3-Codexではなく、gpt-oss-120Bアーキテクチャに基づきGPT-5.3-Codexで蒸留訓練された小型モデルであり、パラメータ数はオリジナルの10分の1以下です。
SemiAnalysisはこの点を明言します:Cerebrasのチップは現時点では比較的小型のモデルにしか経済的に適していません。1兆パラ、100万トークン超の最新AIワークロードの場合、OpenAIがCerebrasで動かすには大幅なコストプレミアムを甘受し、実際のインタラクション速度は毎秒1000トークンを下回る可能性が高いです。
しかし、この見立ての背後には重要な変数があります——それはアルゴリズム進歩の速度です。SemiAnalysisは、120BパラメータモデルがGPT-5.5レベルの知能に達するのは1年もかからないかもしれないとする。そうなれば、「より高い知能より圧倒的な速度を選ぶ」価値命題は大きく変質——今日のエンジニアたちがOpus 4.7の知能よりOpus 4.6高速モードの体験を選ぶように、速度優先の時代となります。
750MWの初期コミットメントは既にロックされています。本当の問題は——120Bモデルの知能が現在の最先端に追いついたとき、OpenAIが購入オプションを実際に行使し、契約スケールを2GWやそれ以上へ拡大するかどうかです。この答えはCerebrasのIPOバリュエーションが実現するか、推論戦争の次の主役が誰なのか、決することになるでしょう。
免責事項:本記事の内容はあくまでも筆者の意見を反映したものであり、いかなる立場においても当プラットフォームを代表するものではありません。また、本記事は投資判断の参考となることを目的としたものではありません。
こちらもいかがですか?
BGSC24時間で89.3%の変動:トークンバーン効果により価格が激しく変動
謎の資金が米国債のプットオプションを大量購入、来月長期債が歴史的安値を下回ることに賭け
原油の多空が100ドルの水準で激戦、債券市場はひそかに世界の資産に一撃
米国のインフレ上昇で利上げ期待が高まり、米国株のハイテク銘柄はエネルギー価格上昇のセンチメントに鈍感に。日本銀行の一部委員は早期利上げを支持---0518マクロ要約