En resumen
- DeepSeek V4 podría lanzarse en unas semanas, apuntando a un rendimiento de codificación de nivel élite.
- Personas con información interna afirman que podría superar a Claude y ChatGPT en tareas de código de contexto largo.
- Los desarrolladores ya están entusiasmados ante una posible disrupción.
Según se informa, DeepSeek planea lanzar su modelo V4 alrededor de mediados de febrero, y si las pruebas internas son un indicio, los gigantes de la IA de Silicon Valley deberían estar nerviosos.
La startup de IA con sede en Hangzhou podría estar apuntando a un lanzamiento alrededor del 17 de febrero—Año Nuevo Lunar, naturalmente—con un modelo diseñado específicamente para tareas de codificación, según
. Personas con conocimiento directo del proyecto afirman que V4 supera tanto a Claude de Anthropic como a la serie GPT de OpenAI en pruebas internas, particularmente al manejar indicaciones de código extremadamente largas.
Por supuesto, no se ha compartido públicamente ningún benchmark o información sobre el modelo, por lo que es imposible verificar directamente tales afirmaciones. DeepSeek tampoco ha confirmado los rumores.
Aun así, la comunidad de desarrolladores no está esperando una palabra oficial. Los foros de Reddit r/DeepSeek y r/LocalLLaMA ya están que arden, los usuarios están acumulando créditos de API, y los entusiastas en X han compartido rápidamente sus predicciones de que V4 podría consolidar la posición de DeepSeek como el desvalido rebelde que se niega a jugar bajo las reglas multimillonarias de Silicon Valley.
Anthropic bloqueó las suscripciones de Claude en aplicaciones de terceros como OpenCode, y supuestamente cortó el acceso a xAI y OpenAI.
Claude y Claude Code son geniales, pero aún no son 10 veces mejores. Esto solo hará que otros laboratorios avancen más rápido en sus modelos/agentes de codificación.
Se rumorea que DeepSeek V4 aparecerá…
— Yuchen Jin (@Yuchenj_UW) 9 de enero de 2026
Esta no sería la primera disrupción de DeepSeek. Cuando la compañía lanzó su modelo de razonamiento R1 en enero de 2025, provocó una venta masiva de un billón de dólares en los mercados globales.
¿La razón? R1 de DeepSeek igualó al modelo o1 de OpenAI en benchmarks de matemáticas y razonamiento a pesar de que, según se informa, solo costó 6 millones de dólares desarrollarlo—aproximadamente 68 veces menos que lo que gastaban los competidores. Su modelo V3 luego alcanzó un 90,2% en el benchmark MATH-500, superando el 78,3% de Claude, y la actualización reciente “V3.2 Speciale” mejoró aún más su rendimiento.
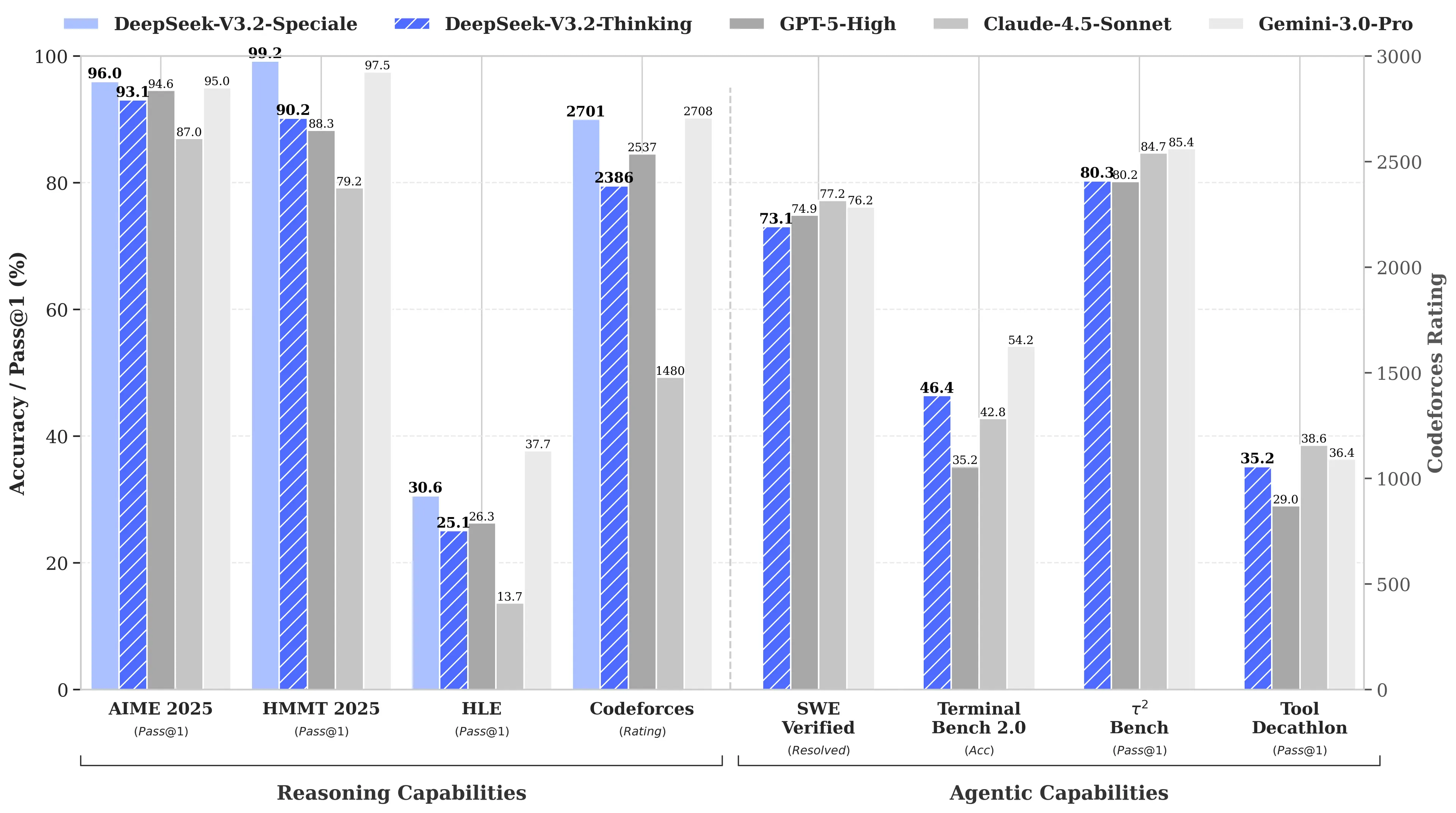
Imagen: DeepSeek
El enfoque en codificación de V4 sería un giro estratégico. Mientras que R1 enfatizaba el razonamiento puro—lógica, matemáticas, pruebas formales—V4 es un modelo híbrido (razonamiento y tareas no relacionadas con razonamiento) que apunta al mercado de desarrolladores empresariales donde la generación de código de alta precisión se traduce directamente en ingresos.
Para reclamar el dominio, V4 tendría que superar a Claude Opus 4.5, que actualmente ostenta el récord de SWE-bench Verified con un 80,9%. Pero si los lanzamientos anteriores de DeepSeek sirven de guía, esto puede no ser imposible de lograr incluso con todas las limitaciones que enfrenta un laboratorio de IA chino.
El secreto no tan secreto
Suponiendo que los rumores sean ciertos, ¿cómo puede este pequeño laboratorio lograr tal hazaña?
El arma secreta de la compañía podría estar contenida en su artículo de investigación del 1 de enero: Manifold-Constrained Hyper-Connections, o mHC. Coescrito por el fundador Liang Wenfeng, el nuevo método de entrenamiento aborda un problema fundamental en la escalabilidad de grandes modelos de lenguaje: cómo expandir la capacidad de un modelo sin que se vuelva inestable o explote durante el entrenamiento.
Las arquitecturas tradicionales de IA fuerzan toda la información a través de un solo canal estrecho. mHC ensancha ese canal en múltiples flujos que pueden intercambiar información sin causar el colapso del entrenamiento.
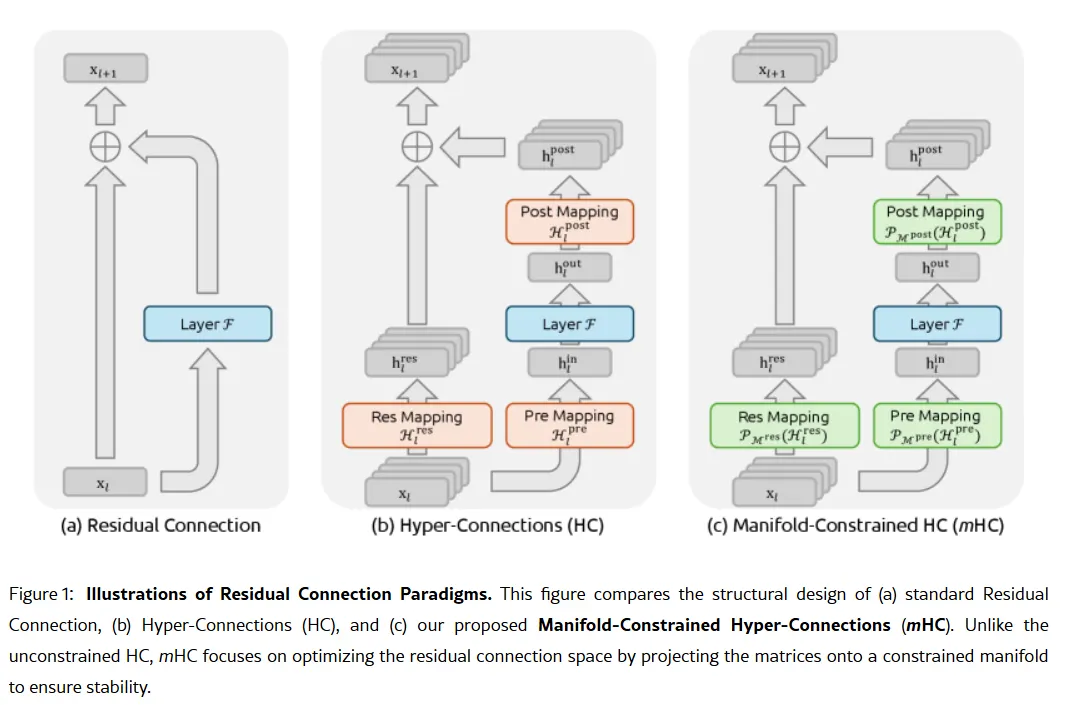
Imagen: DeepSeek
Wei Sun, analista principal de IA en Counterpoint Research, calificó a mHC como un "avance sorprendente" en comentarios a
. La técnica, dijo, demuestra que DeepSeek puede "eludir los cuellos de botella de cómputo y desbloquear saltos en inteligencia", incluso con acceso limitado a chips avanzados debido a las restricciones de exportación de EE. UU.
Lian Jye Su, analista jefe en Omdia, señaló que la disposición de DeepSeek a publicar sus métodos indica una "nueva confianza en la industria de IA china". El enfoque open source de la compañía la ha convertido en la favorita de desarrolladores que la ven como el reflejo de lo que OpenAI solía ser antes de girar hacia modelos cerrados y rondas de financiación multimillonarias.
No todos están convencidos. Algunos desarrolladores en Reddit se quejan de que los modelos de razonamiento de DeepSeek desperdician recursos de cómputo en tareas simples, mientras que los críticos argumentan que los benchmarks de la compañía no reflejan la complejidad del mundo real. Un post de Medium titulado "DeepSeek Apesta—Y ya no pretendo que no" se volvió viral en abril de 2025, acusando a los modelos de producir "código genérico con errores" y "librerías inventadas".
DeepSeek también arrastra problemas. Las preocupaciones por la privacidad han perseguido a la compañía, con algunos gobiernos prohibiendo la app nativa de DeepSeek. Los lazos de la compañía con China y las dudas sobre la censura en sus modelos añaden fricción geopolítica a los debates técnicos.
Aun así, el impulso es innegable. DeepSeek ha sido ampliamente adoptado en Asia, y si V4 cumple sus promesas en codificación, la adopción empresarial en Occidente podría seguir.
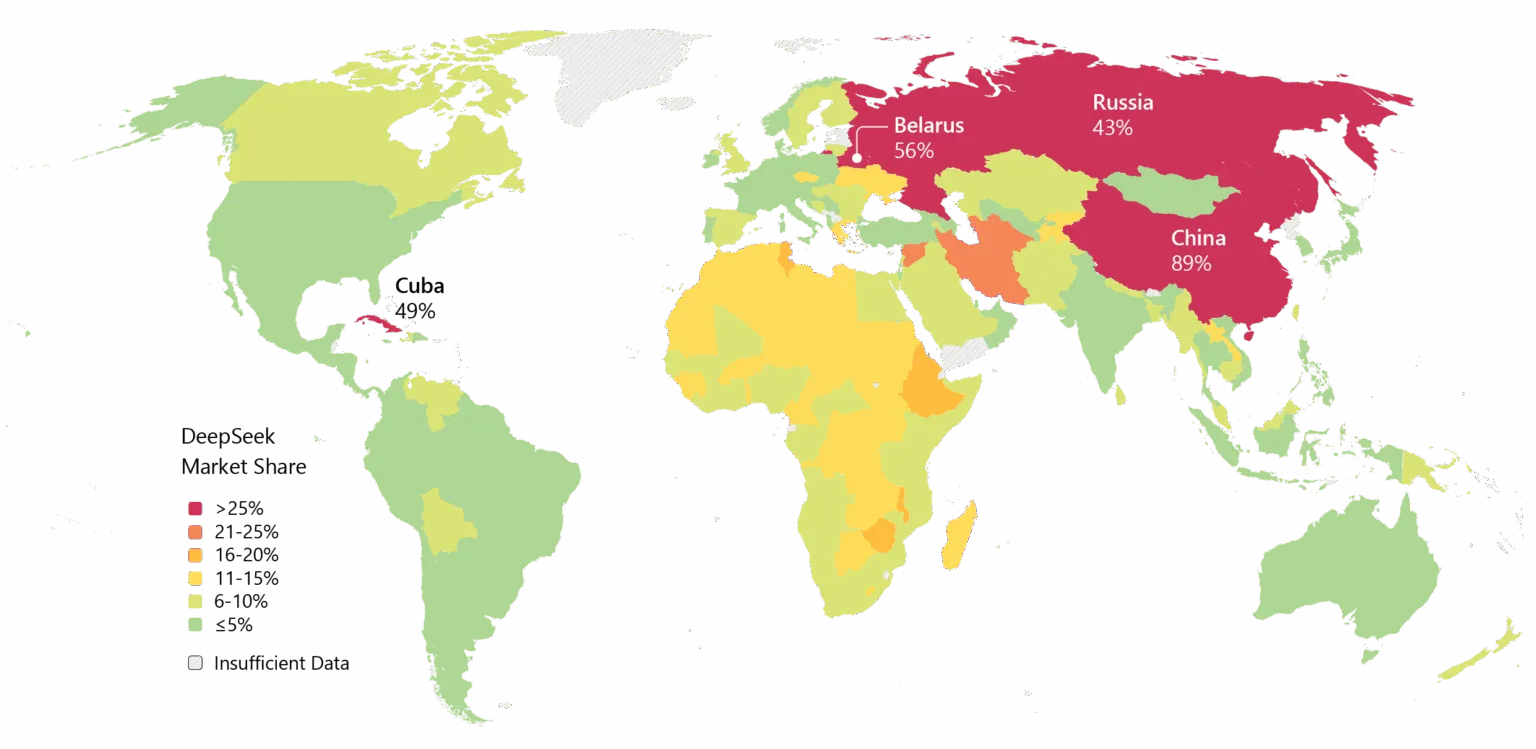
Imagen: Microsoft
También está el factor tiempo. Según
, DeepSeek había planeado originalmente lanzar su modelo R2 en mayo de 2025, pero extendió el plazo después de que el fundador Liang quedara insatisfecho con su rendimiento. Ahora, con V4 supuestamente apuntando a febrero y R2 posiblemente siguiéndole en agosto, la compañía avanza a un ritmo que sugiere urgencia—o confianza. Quizás ambas.


