
Estreno en 2026, Jensen Huang lanza una "bomba nuclear" de 2.5 toneladas en el evento|CES2026

Show original
By:爱范儿
Bitget offers one-stop trading for cryptocurrencies, stocks, and gold. Trade now!
A welcome pack worth 6200 USDT for new users! Sign up now!
*Al final hay un pequeño video sorpresa. Esta es la primera vez en 5 años que NVIDIA no presenta una tarjeta gráfica de consumo en el CES. El CEO Jensen Huang caminó con paso firme hacia el centro del escenario de NVIDIA Live, luciendo la misma chaqueta de piel de cocodrilo brillante del año pasado.  A diferencia del año pasado, cuando ofreció una keynote individual, en 2026 Jensen Huang tuvo una agenda apretada. Desde NVIDIA Live hasta el diálogo industrial de IA de Siemens, y luego en Lenovo TechWorld, participó en tres eventos en 48 horas. La última vez, presentó la serie de tarjetas gráficas RTX 50 en el CES. Pero esta vez, la IA física, la robótica y una “ bomba nuclear empresarial ” de 2.5 toneladas, fueron los verdaderos protagonistas. Plataforma de computación Vera Rubin hace su debut, mientras más compras, más ahorras Durante la presentación, el siempre innovador Jensen Huang llevó al escenario un bastidor de servidor de IA de 2.5 toneladas, introduciendo así el enfoque principal del evento: la plataforma de computación Vera Rubin, nombrada en honor a la astrónoma que descubrió la materia oscura, con un solo objetivo: Acelerar la velocidad de entrenamiento de IA y anticipar la llegada de la próxima generación de modelos.
A diferencia del año pasado, cuando ofreció una keynote individual, en 2026 Jensen Huang tuvo una agenda apretada. Desde NVIDIA Live hasta el diálogo industrial de IA de Siemens, y luego en Lenovo TechWorld, participó en tres eventos en 48 horas. La última vez, presentó la serie de tarjetas gráficas RTX 50 en el CES. Pero esta vez, la IA física, la robótica y una “ bomba nuclear empresarial ” de 2.5 toneladas, fueron los verdaderos protagonistas. Plataforma de computación Vera Rubin hace su debut, mientras más compras, más ahorras Durante la presentación, el siempre innovador Jensen Huang llevó al escenario un bastidor de servidor de IA de 2.5 toneladas, introduciendo así el enfoque principal del evento: la plataforma de computación Vera Rubin, nombrada en honor a la astrónoma que descubrió la materia oscura, con un solo objetivo: Acelerar la velocidad de entrenamiento de IA y anticipar la llegada de la próxima generación de modelos.  Por lo general, hay una regla interna en NVIDIA: cada generación de productos solo cambia 1-2 chips como máximo. Pero esta vez, Vera Rubin rompió con la norma, rediseñando de una vez 6 chips y ya ha entrado en fase de producción masiva.
Por lo general, hay una regla interna en NVIDIA: cada generación de productos solo cambia 1-2 chips como máximo. Pero esta vez, Vera Rubin rompió con la norma, rediseñando de una vez 6 chips y ya ha entrado en fase de producción masiva.
La razón principal es que, con la desaceleración de la Ley de Moore, las formas tradicionales de mejorar el rendimiento ya no pueden seguir el ritmo del crecimiento anual por diez de los modelos de IA, por lo que NVIDIA optó por un “diseño de colaboración extrema”: innovando simultáneamente en todos los chips y niveles de la plataforma. Estos 6 chips son: 1. Vera CPU: - 88 núcleos Olympus personalizados por NVIDIA - Tecnología de multihilo espacial de NVIDIA, soporta 176 hilos - Ancho de banda NVLink C2C de 1.8 TB/s - Memoria del sistema de 1.5 TB (3 veces la de Grace) - Ancho de banda LPDDR5X de 1.2 TB/s - 227 mil millones de transistores
Estos 6 chips son: 1. Vera CPU: - 88 núcleos Olympus personalizados por NVIDIA - Tecnología de multihilo espacial de NVIDIA, soporta 176 hilos - Ancho de banda NVLink C2C de 1.8 TB/s - Memoria del sistema de 1.5 TB (3 veces la de Grace) - Ancho de banda LPDDR5X de 1.2 TB/s - 227 mil millones de transistores  2. Rubin GPU: - Potencia de inferencia NVFP4 de 50 PFLOPS, 5 veces la de Blackwell de la generación anterior - 336 mil millones de transistores, 1.6 veces más que Blackwell - Incorpora la tercera generación de motores Transformer, capaz de ajustar dinámicamente la precisión según las necesidades del modelo Transformer
2. Rubin GPU: - Potencia de inferencia NVFP4 de 50 PFLOPS, 5 veces la de Blackwell de la generación anterior - 336 mil millones de transistores, 1.6 veces más que Blackwell - Incorpora la tercera generación de motores Transformer, capaz de ajustar dinámicamente la precisión según las necesidades del modelo Transformer  3. Tarjeta de red ConnectX-9: - Ethernet de 800 Gb/s basado en 200G PAM4 SerDes - RDMA programable y acelerador de ruta de datos - Certificaciones CNSA y FIPS - 23 mil millones de transistores
3. Tarjeta de red ConnectX-9: - Ethernet de 800 Gb/s basado en 200G PAM4 SerDes - RDMA programable y acelerador de ruta de datos - Certificaciones CNSA y FIPS - 23 mil millones de transistores  4. BlueField-4 DPU: - Motor de extremo a extremo diseñado para la nueva generación de plataformas de almacenamiento de IA - DPU de 800G Gb/s para SmartNIC y procesadores de almacenamiento - CPU Grace de 64 núcleos combinado con ConnectX-9 - 126 mil millones de transistores
4. BlueField-4 DPU: - Motor de extremo a extremo diseñado para la nueva generación de plataformas de almacenamiento de IA - DPU de 800G Gb/s para SmartNIC y procesadores de almacenamiento - CPU Grace de 64 núcleos combinado con ConnectX-9 - 126 mil millones de transistores  5. Chip conmutador NVLink-6: - Conecta 18 nodos de cómputo, soportando hasta 72 GPUs Rubin funcionando en conjunto como un solo sistema - Bajo la arquitectura NVLink 6, cada GPU puede alcanzar 3.6 TB/s de ancho de banda de comunicación all-to-all - Utiliza 400G SerDes, soporta In-Network SHARP Collectives, permitiendo operaciones de comunicación colectiva dentro de la red de conmutadores
5. Chip conmutador NVLink-6: - Conecta 18 nodos de cómputo, soportando hasta 72 GPUs Rubin funcionando en conjunto como un solo sistema - Bajo la arquitectura NVLink 6, cada GPU puede alcanzar 3.6 TB/s de ancho de banda de comunicación all-to-all - Utiliza 400G SerDes, soporta In-Network SHARP Collectives, permitiendo operaciones de comunicación colectiva dentro de la red de conmutadores  6. Chip conmutador óptico Ethernet Spectrum-6 - 512 canales, cada uno de 200Gbps, para transferencias de datos ultrarrápidas - Tecnología de silicio fotónico integrada por TSMC COOP - Interfaz óptica de copackaged optics - 352 mil millones de transistores
6. Chip conmutador óptico Ethernet Spectrum-6 - 512 canales, cada uno de 200Gbps, para transferencias de datos ultrarrápidas - Tecnología de silicio fotónico integrada por TSMC COOP - Interfaz óptica de copackaged optics - 352 mil millones de transistores  Gracias a la integración profunda de los 6 chips, el sistema Vera Rubin NVL72 ofrece mejoras integrales respecto a la generación anterior Blackwell. En tareas de inferencia NVFP4, este chip alcanza una impresionante capacidad de 3.6 EFLOPS, 5 veces más que la anterior arquitectura Blackwell. En entrenamiento NVFP4, el rendimiento llega a 2.5 EFLOPS, un aumento de 3.5 veces. En cuanto a capacidad de almacenamiento, NVL72 está equipado con 54TB de memoria LPDDR5X, 3 veces el producto anterior. La memoria HBM (de alto ancho de banda) alcanza 20.7TB, un 1.5x más. En ancho de banda, la HBM4 llega a 1.6 PB/s, 2.8x más; y el ancho de banda Scale-Up llega a 260 TB/s, el doble. A pesar de estas mejoras, la cantidad de transistores solo aumentó 1.7 veces, alcanzando los 2.2 billones, demostrando la capacidad innovadora en fabricación de semiconductores.
Gracias a la integración profunda de los 6 chips, el sistema Vera Rubin NVL72 ofrece mejoras integrales respecto a la generación anterior Blackwell. En tareas de inferencia NVFP4, este chip alcanza una impresionante capacidad de 3.6 EFLOPS, 5 veces más que la anterior arquitectura Blackwell. En entrenamiento NVFP4, el rendimiento llega a 2.5 EFLOPS, un aumento de 3.5 veces. En cuanto a capacidad de almacenamiento, NVL72 está equipado con 54TB de memoria LPDDR5X, 3 veces el producto anterior. La memoria HBM (de alto ancho de banda) alcanza 20.7TB, un 1.5x más. En ancho de banda, la HBM4 llega a 1.6 PB/s, 2.8x más; y el ancho de banda Scale-Up llega a 260 TB/s, el doble. A pesar de estas mejoras, la cantidad de transistores solo aumentó 1.7 veces, alcanzando los 2.2 billones, demostrando la capacidad innovadora en fabricación de semiconductores.  En términos de ingeniería, Vera Rubin también aporta avances tecnológicos. Antes, los nodos de supercomputadoras requerían 43 cables y 2 horas para ensamblar, además de ser propensos a errores. Ahora, el nodo Vera Rubin no usa cables, solo 6 tuberías de refrigeración líquida, y se monta en 5 minutos. Aún más impresionante, la parte trasera del bastidor está llena de cerca de 3.2 km de cable de cobre; 5000 cables conforman la red troncal NVLink, alcanzando 400Gbps. Como dice Jensen Huang: “Puede pesar varias centenas de libras, solo un CEO robusto puede manejar este trabajo”. En el mundo de la IA, el tiempo es dinero: para entrenar un modelo de 10 billones de parámetros, Rubin solo necesita 1/4 de los sistemas Blackwell, y el costo por generar un Token es alrededor de 1/10 del de Blackwell.
En términos de ingeniería, Vera Rubin también aporta avances tecnológicos. Antes, los nodos de supercomputadoras requerían 43 cables y 2 horas para ensamblar, además de ser propensos a errores. Ahora, el nodo Vera Rubin no usa cables, solo 6 tuberías de refrigeración líquida, y se monta en 5 minutos. Aún más impresionante, la parte trasera del bastidor está llena de cerca de 3.2 km de cable de cobre; 5000 cables conforman la red troncal NVLink, alcanzando 400Gbps. Como dice Jensen Huang: “Puede pesar varias centenas de libras, solo un CEO robusto puede manejar este trabajo”. En el mundo de la IA, el tiempo es dinero: para entrenar un modelo de 10 billones de parámetros, Rubin solo necesita 1/4 de los sistemas Blackwell, y el costo por generar un Token es alrededor de 1/10 del de Blackwell. 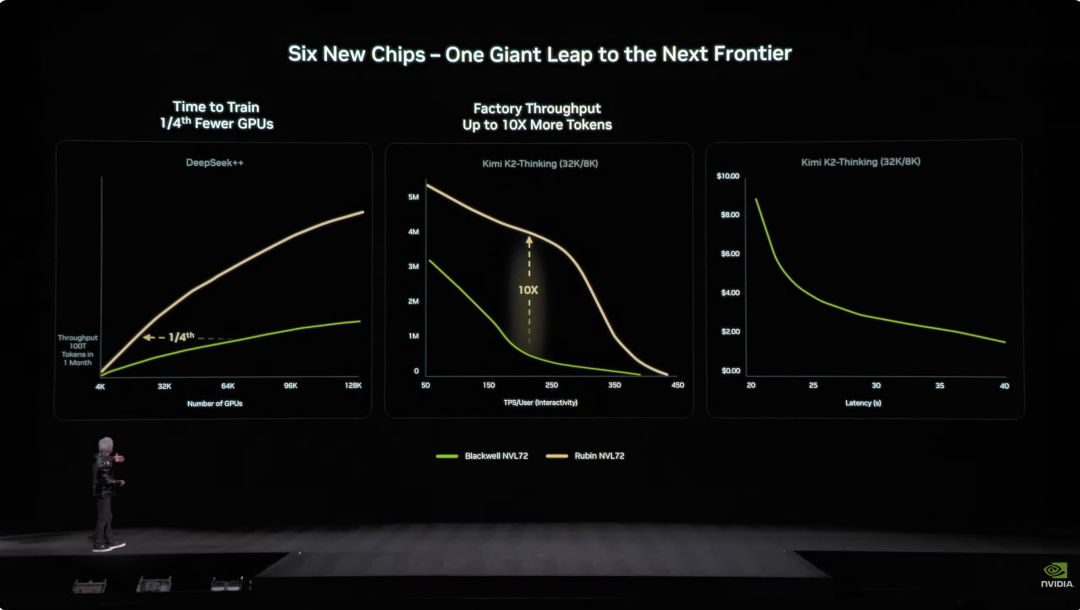 Además, aunque el consumo energético de Rubin es el doble que el de Grace Blackwell, el rendimiento supera con creces el aumento de consumo: el rendimiento de inferencia mejora 5 veces y el de entrenamiento 3.5 veces. Aún más importante, en comparación con Blackwell, Rubin mejora la tasa de tokens de IA generados por vatio y dólar (throughput) en 10 veces. Para un centro de datos de 1 GW que cuesta 50 mil millones de dólares, esto significa duplicar directamente su capacidad de ingresos. El mayor dolor de cabeza de la industria de IA era la falta de memoria de contexto. Específicamente, la IA genera un “KV Cache” (memoria de clave-valor), que es su “memoria de trabajo”. El problema es que, a medida que la conversación se alarga y el modelo crece, la memoria HBM se queda corta.
Además, aunque el consumo energético de Rubin es el doble que el de Grace Blackwell, el rendimiento supera con creces el aumento de consumo: el rendimiento de inferencia mejora 5 veces y el de entrenamiento 3.5 veces. Aún más importante, en comparación con Blackwell, Rubin mejora la tasa de tokens de IA generados por vatio y dólar (throughput) en 10 veces. Para un centro de datos de 1 GW que cuesta 50 mil millones de dólares, esto significa duplicar directamente su capacidad de ingresos. El mayor dolor de cabeza de la industria de IA era la falta de memoria de contexto. Específicamente, la IA genera un “KV Cache” (memoria de clave-valor), que es su “memoria de trabajo”. El problema es que, a medida que la conversación se alarga y el modelo crece, la memoria HBM se queda corta.  El año pasado NVIDIA lanzó la arquitectura Grace-Blackwell para expandir la memoria, pero aún no era suficiente. La solución de Vera Rubin es desplegar procesadores BlueField-4 dentro del bastidor, dedicados a gestionar el KV Cache. Cada nodo tiene 4 BlueField-4, cada uno con 150TB de memoria de contexto, distribuida a las GPUs, proporcionando a cada GPU 16TB extra de memoria (la GPU solo tiene alrededor de 1TB propia), manteniendo un ancho de banda de 200Gbps, sin sacrificar velocidad. Pero solo tener capacidad no basta; para que las “notas adhesivas” dispersas en decenas de bastidores y miles de GPUs funcionen como una sola memoria, la red debe ser “grande, rápida y estable”. Aquí entra Spectrum-X. Spectrum-X es la primera plataforma mundial de red Ethernet “diseñada para IA generativa” de extremo a extremo. La última generación, fabricada con TSMC COOP, integra tecnología de silicio fotónico y 512 canales × 200Gbps de velocidad. Jensen Huang hizo cálculos: un centro de datos de 1 GW cuesta 50 mil millones de dólares y Spectrum-X puede mejorar el throughput en un 25%, lo que equivale a ahorrar 5 mil millones de dólares. “Se podría decir que este sistema de red es prácticamente gratis”. En cuanto a seguridad, Vera Rubin también soporta computación confidencial. Todos los datos están cifrados durante la transmisión, almacenamiento y cálculo, incluyendo los buses PCIe, NVLink y la comunicación CPU-GPU. Las empresas pueden desplegar sus modelos en sistemas externos sin preocuparse por fugas de datos. DeepSeek sorprendió al mundo, el open source y los agentes inteligentes son la corriente principal de la IA Tras lo más destacado, volvamos al inicio del discurso. Jensen Huang lanzó un dato impactante: en la última década, unos 10 billones de dólares en recursos computacionales están siendo completamente modernizados. Pero no se trata solo de una actualización de hardware, sino de un cambio de paradigma en el software. Hizo especial mención a los modelos de agentes inteligentes (Agentic), destacando a Cursor, que ha transformado completamente la programación interna de NVIDIA.
El año pasado NVIDIA lanzó la arquitectura Grace-Blackwell para expandir la memoria, pero aún no era suficiente. La solución de Vera Rubin es desplegar procesadores BlueField-4 dentro del bastidor, dedicados a gestionar el KV Cache. Cada nodo tiene 4 BlueField-4, cada uno con 150TB de memoria de contexto, distribuida a las GPUs, proporcionando a cada GPU 16TB extra de memoria (la GPU solo tiene alrededor de 1TB propia), manteniendo un ancho de banda de 200Gbps, sin sacrificar velocidad. Pero solo tener capacidad no basta; para que las “notas adhesivas” dispersas en decenas de bastidores y miles de GPUs funcionen como una sola memoria, la red debe ser “grande, rápida y estable”. Aquí entra Spectrum-X. Spectrum-X es la primera plataforma mundial de red Ethernet “diseñada para IA generativa” de extremo a extremo. La última generación, fabricada con TSMC COOP, integra tecnología de silicio fotónico y 512 canales × 200Gbps de velocidad. Jensen Huang hizo cálculos: un centro de datos de 1 GW cuesta 50 mil millones de dólares y Spectrum-X puede mejorar el throughput en un 25%, lo que equivale a ahorrar 5 mil millones de dólares. “Se podría decir que este sistema de red es prácticamente gratis”. En cuanto a seguridad, Vera Rubin también soporta computación confidencial. Todos los datos están cifrados durante la transmisión, almacenamiento y cálculo, incluyendo los buses PCIe, NVLink y la comunicación CPU-GPU. Las empresas pueden desplegar sus modelos en sistemas externos sin preocuparse por fugas de datos. DeepSeek sorprendió al mundo, el open source y los agentes inteligentes son la corriente principal de la IA Tras lo más destacado, volvamos al inicio del discurso. Jensen Huang lanzó un dato impactante: en la última década, unos 10 billones de dólares en recursos computacionales están siendo completamente modernizados. Pero no se trata solo de una actualización de hardware, sino de un cambio de paradigma en el software. Hizo especial mención a los modelos de agentes inteligentes (Agentic), destacando a Cursor, que ha transformado completamente la programación interna de NVIDIA. 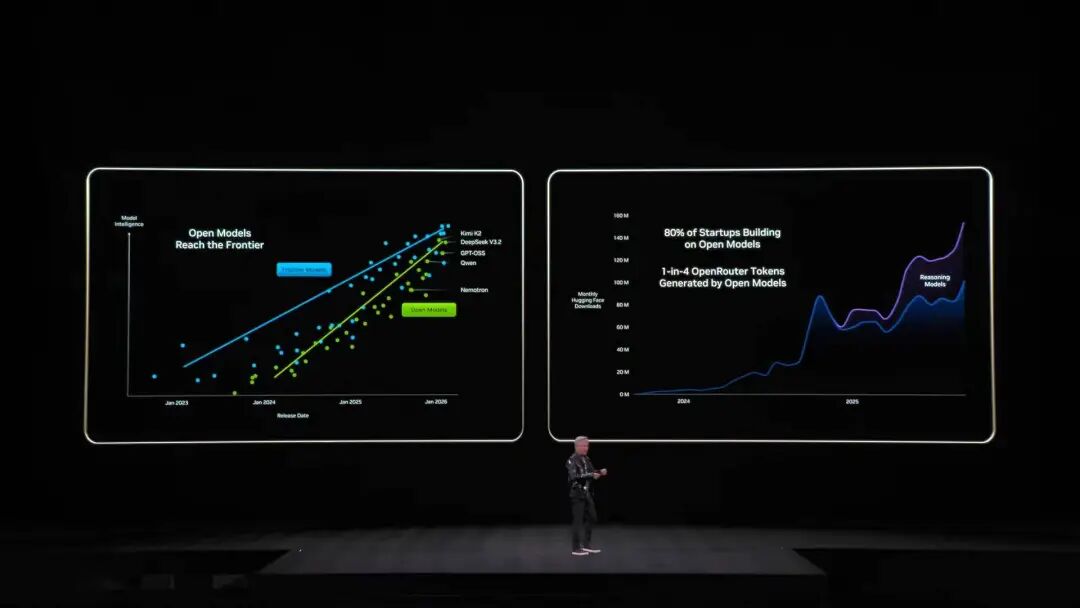 Lo que más entusiasmó al público fue su alto reconocimiento a la comunidad open source. Jensen Huang afirmó que el avance de DeepSeek V1 el año pasado tomó por sorpresa al mundo: como el primer sistema de inferencia open source, desencadenó una ola de desarrollo en la industria. En la diapositiva, los jugadores chinos Kimi k2 y DeepSeek V3.2 fueron los primeros y segundos en open source. Jensen Huang considera que, aunque los modelos open source pueden estar unos seis meses por detrás de los más avanzados, cada seis meses surge un nuevo modelo. Esta velocidad de iteración hace que ni startups, ni grandes empresas ni investigadores quieran quedarse atrás, incluida NVIDIA. Así que esta vez tampoco se limitaron a vender palas y tarjetas gráficas; NVIDIA construyó la supercomputadora DGX Cloud valorada en varios miles de millones de dólares y desarrolló modelos de vanguardia como La Proteina (síntesis de proteínas) y OpenFold 3.
Lo que más entusiasmó al público fue su alto reconocimiento a la comunidad open source. Jensen Huang afirmó que el avance de DeepSeek V1 el año pasado tomó por sorpresa al mundo: como el primer sistema de inferencia open source, desencadenó una ola de desarrollo en la industria. En la diapositiva, los jugadores chinos Kimi k2 y DeepSeek V3.2 fueron los primeros y segundos en open source. Jensen Huang considera que, aunque los modelos open source pueden estar unos seis meses por detrás de los más avanzados, cada seis meses surge un nuevo modelo. Esta velocidad de iteración hace que ni startups, ni grandes empresas ni investigadores quieran quedarse atrás, incluida NVIDIA. Así que esta vez tampoco se limitaron a vender palas y tarjetas gráficas; NVIDIA construyó la supercomputadora DGX Cloud valorada en varios miles de millones de dólares y desarrolló modelos de vanguardia como La Proteina (síntesis de proteínas) y OpenFold 3.  El ecosistema de modelos open source de NVIDIA abarca biomedicina, IA física, modelos de agentes, robótica y conducción autónoma, entre otros Y varias versiones open source de la familia de modelos Nemotron de NVIDIA también fueron protagonistas del discurso. Incluyen modelos de voz, multimodales, de recuperación aumentada y de seguridad, entre otros; Jensen Huang mencionó que los modelos open source de Nemotron han destacado en múltiples rankings y están siendo ampliamente adoptados por empresas. ¿Qué es la IA física? Lanzamiento simultáneo de decenas de modelos Si los grandes modelos de lenguaje resuelven los problemas del “mundo digital”, la próxima ambición de NVIDIA es claramente conquistar el “mundo físico”. Jensen Huang explicó que para que la IA entienda las leyes físicas y sobreviva en el mundo real, los datos son extremadamente escasos. Además de los modelos open source de agentes Nemotron, propuso una arquitectura de “tres computadoras” para construir IA física (Physical AI).
El ecosistema de modelos open source de NVIDIA abarca biomedicina, IA física, modelos de agentes, robótica y conducción autónoma, entre otros Y varias versiones open source de la familia de modelos Nemotron de NVIDIA también fueron protagonistas del discurso. Incluyen modelos de voz, multimodales, de recuperación aumentada y de seguridad, entre otros; Jensen Huang mencionó que los modelos open source de Nemotron han destacado en múltiples rankings y están siendo ampliamente adoptados por empresas. ¿Qué es la IA física? Lanzamiento simultáneo de decenas de modelos Si los grandes modelos de lenguaje resuelven los problemas del “mundo digital”, la próxima ambición de NVIDIA es claramente conquistar el “mundo físico”. Jensen Huang explicó que para que la IA entienda las leyes físicas y sobreviva en el mundo real, los datos son extremadamente escasos. Además de los modelos open source de agentes Nemotron, propuso una arquitectura de “tres computadoras” para construir IA física (Physical AI). 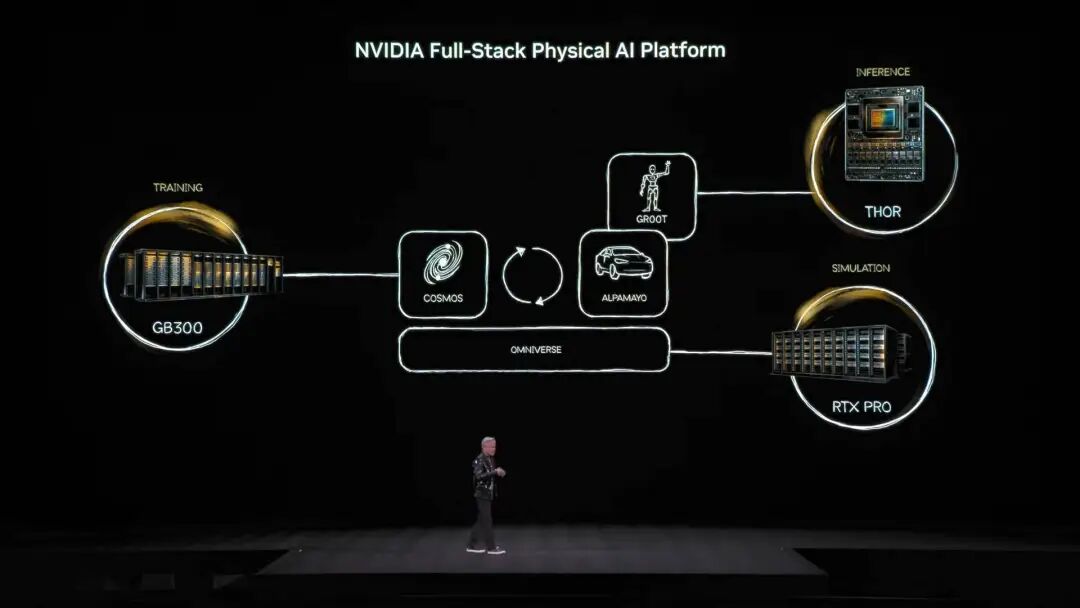
Computadora de entrenamiento, es decir, la que conocemos, construida con tarjetas gráficas de entrenamiento como la arquitectura GB300 mencionada en la imagen.
Computadora de inferencia, el “cerebelo” que opera en el borde del robot o del coche, responsable de la ejecución en tiempo real.
Computadora de simulación, incluyendo Omniverse y Cosmos, que proporciona a la IA un entorno virtual de entrenamiento donde aprender retroalimentación física en simulación. El sistema Cosmos puede generar gran cantidad de entornos de entrenamiento de IA para el mundo físico Basado en esta arquitectura, Jensen Huang presentó oficialmente el impactante Alpamayo, el primer modelo de conducción autónoma del mundo con capacidades de pensamiento y razonamiento.
El sistema Cosmos puede generar gran cantidad de entornos de entrenamiento de IA para el mundo físico Basado en esta arquitectura, Jensen Huang presentó oficialmente el impactante Alpamayo, el primer modelo de conducción autónoma del mundo con capacidades de pensamiento y razonamiento.  A diferencia de la conducción autónoma tradicional, Alpamayo es un sistema entrenado de extremo a extremo. Su innovación radica en resolver el “problema de la larga cola” de la conducción autónoma. Ante escenarios complejos e inéditos, Alpamayo ya no ejecuta instrucciones rígidas, sino que razona como un conductor humano. “Te dirá qué va a hacer a continuación y por qué lo decide”. En la demostración, la conducción era sorprendentemente natural, siendo capaz de descomponer escenarios extremadamente complejos en elementos de sentido común. Fuera de la demo, esto no es solo teoría. Jensen Huang anunció que el Mercedes CLA con la tecnología Alpamayo se lanzará oficialmente en EE. UU. en el primer trimestre de este año, y luego llegará a Europa y Asia.
A diferencia de la conducción autónoma tradicional, Alpamayo es un sistema entrenado de extremo a extremo. Su innovación radica en resolver el “problema de la larga cola” de la conducción autónoma. Ante escenarios complejos e inéditos, Alpamayo ya no ejecuta instrucciones rígidas, sino que razona como un conductor humano. “Te dirá qué va a hacer a continuación y por qué lo decide”. En la demostración, la conducción era sorprendentemente natural, siendo capaz de descomponer escenarios extremadamente complejos en elementos de sentido común. Fuera de la demo, esto no es solo teoría. Jensen Huang anunció que el Mercedes CLA con la tecnología Alpamayo se lanzará oficialmente en EE. UU. en el primer trimestre de este año, y luego llegará a Europa y Asia.  Este coche fue calificado por NCAP como el más seguro del mundo, gracias a la exclusiva arquitectura de “doble pila de seguridad” de NVIDIA. Cuando el modelo de IA de extremo a extremo no tiene suficiente confianza en la carretera, el sistema cambia inmediatamente al modo de seguridad tradicional y más seguro, asegurando protección total. Durante la presentación, Jensen Huang también mostró la estrategia de robótica de NVIDIA.
Este coche fue calificado por NCAP como el más seguro del mundo, gracias a la exclusiva arquitectura de “doble pila de seguridad” de NVIDIA. Cuando el modelo de IA de extremo a extremo no tiene suficiente confianza en la carretera, el sistema cambia inmediatamente al modo de seguridad tradicional y más seguro, asegurando protección total. Durante la presentación, Jensen Huang también mostró la estrategia de robótica de NVIDIA. 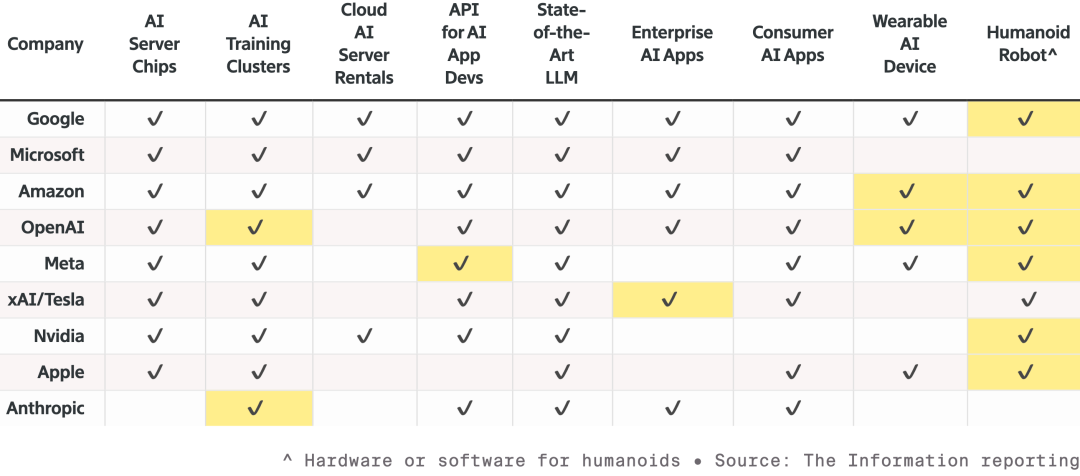 Competencia entre nueve principales fabricantes de IA y hardware afines, todos expandiendo líneas de productos, especialmente en el ámbito de robótica; las celdas resaltadas corresponden a productos lanzados desde el año pasado Todos los robots estarán equipados con el miniordenador Jetson y serán entrenados en el simulador Isaac de la plataforma Omniverse. Además, NVIDIA está integrando esta tecnología en sistemas industriales como Synopsys, Cadence y Siemens.
Competencia entre nueve principales fabricantes de IA y hardware afines, todos expandiendo líneas de productos, especialmente en el ámbito de robótica; las celdas resaltadas corresponden a productos lanzados desde el año pasado Todos los robots estarán equipados con el miniordenador Jetson y serán entrenados en el simulador Isaac de la plataforma Omniverse. Además, NVIDIA está integrando esta tecnología en sistemas industriales como Synopsys, Cadence y Siemens.  Jensen Huang invitó al escenario robots humanoides y cuadrúpedos como los de Boston Dynamics y Agility, enfatizando que el mayor robot es en realidad la propia fábrica De abajo hacia arriba, la visión de NVIDIA es que, en el futuro, el diseño de chips, de sistemas y la simulación de fábricas serán acelerados por la IA física de NVIDIA. Durante la presentación, los robots de Disney también hicieron una aparición especial, y Jensen Huang bromeó con estos adorables robots diciendo: “Serán diseñados en computadoras, fabricados en computadoras e incluso probados y verificados en computadoras antes de enfrentarse realmente a la gravedad”.
Jensen Huang invitó al escenario robots humanoides y cuadrúpedos como los de Boston Dynamics y Agility, enfatizando que el mayor robot es en realidad la propia fábrica De abajo hacia arriba, la visión de NVIDIA es que, en el futuro, el diseño de chips, de sistemas y la simulación de fábricas serán acelerados por la IA física de NVIDIA. Durante la presentación, los robots de Disney también hicieron una aparición especial, y Jensen Huang bromeó con estos adorables robots diciendo: “Serán diseñados en computadoras, fabricados en computadoras e incluso probados y verificados en computadoras antes de enfrentarse realmente a la gravedad”.  Si no fuera Jensen Huang, cualquiera podría pensar que toda la keynote fue el lanzamiento de un fabricante de modelos. En una época donde el escepticismo sobre la “burbuja de IA” es alto y la Ley de Moore se desacelera, Jensen Huang parece necesitar demostrar con hechos lo que la IA puede lograr, para fortalecer la confianza de todos en ella. Además de presentar el nuevo y potente superordenador de IA Vera Rubin para calmar la demanda de cómputo, dedicó más esfuerzo que nunca en aplicaciones y software, tratando de mostrarnos a toda costa los cambios tangibles que la IA traerá. Como dijo Jensen Huang, antes hacían chips para el mundo virtual, ahora ellos mismos demuestran y centran su atención en la IA física representada por la conducción autónoma y robots humanoides, adentrándose en el competitivo mundo físico real. Al fin y al cabo, solo cuando la batalla comienza, el negocio de la “industria militar” puede prosperar. *Por último, aquí va el video sorpresa: Debido al tiempo limitado del discurso en el CES, Jensen Huang no pudo cubrir muchas diapositivas. Así que, en vez de eso, hizo un divertido corto con las diapositivas que no se mostraron. Disfruta⬇️
Si no fuera Jensen Huang, cualquiera podría pensar que toda la keynote fue el lanzamiento de un fabricante de modelos. En una época donde el escepticismo sobre la “burbuja de IA” es alto y la Ley de Moore se desacelera, Jensen Huang parece necesitar demostrar con hechos lo que la IA puede lograr, para fortalecer la confianza de todos en ella. Además de presentar el nuevo y potente superordenador de IA Vera Rubin para calmar la demanda de cómputo, dedicó más esfuerzo que nunca en aplicaciones y software, tratando de mostrarnos a toda costa los cambios tangibles que la IA traerá. Como dijo Jensen Huang, antes hacían chips para el mundo virtual, ahora ellos mismos demuestran y centran su atención en la IA física representada por la conducción autónoma y robots humanoides, adentrándose en el competitivo mundo físico real. Al fin y al cabo, solo cuando la batalla comienza, el negocio de la “industria militar” puede prosperar. *Por último, aquí va el video sorpresa: Debido al tiempo limitado del discurso en el CES, Jensen Huang no pudo cubrir muchas diapositivas. Así que, en vez de eso, hizo un divertido corto con las diapositivas que no se mostraron. Disfruta⬇️ 
A diferencia del año pasado, cuando ofreció una keynote individual, en 2026 Jensen Huang tuvo una agenda apretada. Desde NVIDIA Live hasta el diálogo industrial de IA de Siemens, y luego en Lenovo TechWorld, participó en tres eventos en 48 horas. La última vez, presentó la serie de tarjetas gráficas RTX 50 en el CES. Pero esta vez, la IA física, la robótica y una “ bomba nuclear empresarial ” de 2.5 toneladas, fueron los verdaderos protagonistas. Plataforma de computación Vera Rubin hace su debut, mientras más compras, más ahorras Durante la presentación, el siempre innovador Jensen Huang llevó al escenario un bastidor de servidor de IA de 2.5 toneladas, introduciendo así el enfoque principal del evento: la plataforma de computación Vera Rubin, nombrada en honor a la astrónoma que descubrió la materia oscura, con un solo objetivo: Acelerar la velocidad de entrenamiento de IA y anticipar la llegada de la próxima generación de modelos. Por lo general, hay una regla interna en NVIDIA: cada generación de productos solo cambia 1-2 chips como máximo. Pero esta vez, Vera Rubin rompió con la norma, rediseñando de una vez 6 chips y ya ha entrado en fase de producción masiva. La razón principal es que, con la desaceleración de la Ley de Moore, las formas tradicionales de mejorar el rendimiento ya no pueden seguir el ritmo del crecimiento anual por diez de los modelos de IA, por lo que NVIDIA optó por un “diseño de colaboración extrema”: innovando simultáneamente en todos los chips y niveles de la plataforma.
Estos 6 chips son: 1. Vera CPU: - 88 núcleos Olympus personalizados por NVIDIA - Tecnología de multihilo espacial de NVIDIA, soporta 176 hilos - Ancho de banda NVLink C2C de 1.8 TB/s - Memoria del sistema de 1.5 TB (3 veces la de Grace) - Ancho de banda LPDDR5X de 1.2 TB/s - 227 mil millones de transistores 2. Rubin GPU: - Potencia de inferencia NVFP4 de 50 PFLOPS, 5 veces la de Blackwell de la generación anterior - 336 mil millones de transistores, 1.6 veces más que Blackwell - Incorpora la tercera generación de motores Transformer, capaz de ajustar dinámicamente la precisión según las necesidades del modelo Transformer 3. Tarjeta de red ConnectX-9: - Ethernet de 800 Gb/s basado en 200G PAM4 SerDes - RDMA programable y acelerador de ruta de datos - Certificaciones CNSA y FIPS - 23 mil millones de transistores 4. BlueField-4 DPU: - Motor de extremo a extremo diseñado para la nueva generación de plataformas de almacenamiento de IA - DPU de 800G Gb/s para SmartNIC y procesadores de almacenamiento - CPU Grace de 64 núcleos combinado con ConnectX-9 - 126 mil millones de transistores 5. Chip conmutador NVLink-6: - Conecta 18 nodos de cómputo, soportando hasta 72 GPUs Rubin funcionando en conjunto como un solo sistema - Bajo la arquitectura NVLink 6, cada GPU puede alcanzar 3.6 TB/s de ancho de banda de comunicación all-to-all - Utiliza 400G SerDes, soporta In-Network SHARP Collectives, permitiendo operaciones de comunicación colectiva dentro de la red de conmutadores 6. Chip conmutador óptico Ethernet Spectrum-6 - 512 canales, cada uno de 200Gbps, para transferencias de datos ultrarrápidas - Tecnología de silicio fotónico integrada por TSMC COOP - Interfaz óptica de copackaged optics - 352 mil millones de transistores Gracias a la integración profunda de los 6 chips, el sistema Vera Rubin NVL72 ofrece mejoras integrales respecto a la generación anterior Blackwell. En tareas de inferencia NVFP4, este chip alcanza una impresionante capacidad de 3.6 EFLOPS, 5 veces más que la anterior arquitectura Blackwell. En entrenamiento NVFP4, el rendimiento llega a 2.5 EFLOPS, un aumento de 3.5 veces. En cuanto a capacidad de almacenamiento, NVL72 está equipado con 54TB de memoria LPDDR5X, 3 veces el producto anterior. La memoria HBM (de alto ancho de banda) alcanza 20.7TB, un 1.5x más. En ancho de banda, la HBM4 llega a 1.6 PB/s, 2.8x más; y el ancho de banda Scale-Up llega a 260 TB/s, el doble. A pesar de estas mejoras, la cantidad de transistores solo aumentó 1.7 veces, alcanzando los 2.2 billones, demostrando la capacidad innovadora en fabricación de semiconductores. En términos de ingeniería, Vera Rubin también aporta avances tecnológicos. Antes, los nodos de supercomputadoras requerían 43 cables y 2 horas para ensamblar, además de ser propensos a errores. Ahora, el nodo Vera Rubin no usa cables, solo 6 tuberías de refrigeración líquida, y se monta en 5 minutos. Aún más impresionante, la parte trasera del bastidor está llena de cerca de 3.2 km de cable de cobre; 5000 cables conforman la red troncal NVLink, alcanzando 400Gbps. Como dice Jensen Huang: “Puede pesar varias centenas de libras, solo un CEO robusto puede manejar este trabajo”. En el mundo de la IA, el tiempo es dinero: para entrenar un modelo de 10 billones de parámetros, Rubin solo necesita 1/4 de los sistemas Blackwell, y el costo por generar un Token es alrededor de 1/10 del de Blackwell. Además, aunque el consumo energético de Rubin es el doble que el de Grace Blackwell, el rendimiento supera con creces el aumento de consumo: el rendimiento de inferencia mejora 5 veces y el de entrenamiento 3.5 veces. Aún más importante, en comparación con Blackwell, Rubin mejora la tasa de tokens de IA generados por vatio y dólar (throughput) en 10 veces. Para un centro de datos de 1 GW que cuesta 50 mil millones de dólares, esto significa duplicar directamente su capacidad de ingresos. El mayor dolor de cabeza de la industria de IA era la falta de memoria de contexto. Específicamente, la IA genera un “KV Cache” (memoria de clave-valor), que es su “memoria de trabajo”. El problema es que, a medida que la conversación se alarga y el modelo crece, la memoria HBM se queda corta. El año pasado NVIDIA lanzó la arquitectura Grace-Blackwell para expandir la memoria, pero aún no era suficiente. La solución de Vera Rubin es desplegar procesadores BlueField-4 dentro del bastidor, dedicados a gestionar el KV Cache. Cada nodo tiene 4 BlueField-4, cada uno con 150TB de memoria de contexto, distribuida a las GPUs, proporcionando a cada GPU 16TB extra de memoria (la GPU solo tiene alrededor de 1TB propia), manteniendo un ancho de banda de 200Gbps, sin sacrificar velocidad. Pero solo tener capacidad no basta; para que las “notas adhesivas” dispersas en decenas de bastidores y miles de GPUs funcionen como una sola memoria, la red debe ser “grande, rápida y estable”. Aquí entra Spectrum-X. Spectrum-X es la primera plataforma mundial de red Ethernet “diseñada para IA generativa” de extremo a extremo. La última generación, fabricada con TSMC COOP, integra tecnología de silicio fotónico y 512 canales × 200Gbps de velocidad. Jensen Huang hizo cálculos: un centro de datos de 1 GW cuesta 50 mil millones de dólares y Spectrum-X puede mejorar el throughput en un 25%, lo que equivale a ahorrar 5 mil millones de dólares. “Se podría decir que este sistema de red es prácticamente gratis”. En cuanto a seguridad, Vera Rubin también soporta computación confidencial. Todos los datos están cifrados durante la transmisión, almacenamiento y cálculo, incluyendo los buses PCIe, NVLink y la comunicación CPU-GPU. Las empresas pueden desplegar sus modelos en sistemas externos sin preocuparse por fugas de datos. DeepSeek sorprendió al mundo, el open source y los agentes inteligentes son la corriente principal de la IA Tras lo más destacado, volvamos al inicio del discurso. Jensen Huang lanzó un dato impactante: en la última década, unos 10 billones de dólares en recursos computacionales están siendo completamente modernizados. Pero no se trata solo de una actualización de hardware, sino de un cambio de paradigma en el software. Hizo especial mención a los modelos de agentes inteligentes (Agentic), destacando a Cursor, que ha transformado completamente la programación interna de NVIDIA. Lo que más entusiasmó al público fue su alto reconocimiento a la comunidad open source. Jensen Huang afirmó que el avance de DeepSeek V1 el año pasado tomó por sorpresa al mundo: como el primer sistema de inferencia open source, desencadenó una ola de desarrollo en la industria. En la diapositiva, los jugadores chinos Kimi k2 y DeepSeek V3.2 fueron los primeros y segundos en open source. Jensen Huang considera que, aunque los modelos open source pueden estar unos seis meses por detrás de los más avanzados, cada seis meses surge un nuevo modelo. Esta velocidad de iteración hace que ni startups, ni grandes empresas ni investigadores quieran quedarse atrás, incluida NVIDIA. Así que esta vez tampoco se limitaron a vender palas y tarjetas gráficas; NVIDIA construyó la supercomputadora DGX Cloud valorada en varios miles de millones de dólares y desarrolló modelos de vanguardia como La Proteina (síntesis de proteínas) y OpenFold 3. El ecosistema de modelos open source de NVIDIA abarca biomedicina, IA física, modelos de agentes, robótica y conducción autónoma, entre otros Y varias versiones open source de la familia de modelos Nemotron de NVIDIA también fueron protagonistas del discurso. Incluyen modelos de voz, multimodales, de recuperación aumentada y de seguridad, entre otros; Jensen Huang mencionó que los modelos open source de Nemotron han destacado en múltiples rankings y están siendo ampliamente adoptados por empresas. ¿Qué es la IA física? Lanzamiento simultáneo de decenas de modelos Si los grandes modelos de lenguaje resuelven los problemas del “mundo digital”, la próxima ambición de NVIDIA es claramente conquistar el “mundo físico”. Jensen Huang explicó que para que la IA entienda las leyes físicas y sobreviva en el mundo real, los datos son extremadamente escasos. Además de los modelos open source de agentes Nemotron, propuso una arquitectura de “tres computadoras” para construir IA física (Physical AI). Computadora de entrenamiento, es decir, la que conocemos, construida con tarjetas gráficas de entrenamiento como la arquitectura GB300 mencionada en la imagen.
Computadora de inferencia, el “cerebelo” que opera en el borde del robot o del coche, responsable de la ejecución en tiempo real.
Computadora de simulación, incluyendo Omniverse y Cosmos, que proporciona a la IA un entorno virtual de entrenamiento donde aprender retroalimentación física en simulación.
El sistema Cosmos puede generar gran cantidad de entornos de entrenamiento de IA para el mundo físico Basado en esta arquitectura, Jensen Huang presentó oficialmente el impactante Alpamayo, el primer modelo de conducción autónoma del mundo con capacidades de pensamiento y razonamiento. A diferencia de la conducción autónoma tradicional, Alpamayo es un sistema entrenado de extremo a extremo. Su innovación radica en resolver el “problema de la larga cola” de la conducción autónoma. Ante escenarios complejos e inéditos, Alpamayo ya no ejecuta instrucciones rígidas, sino que razona como un conductor humano. “Te dirá qué va a hacer a continuación y por qué lo decide”. En la demostración, la conducción era sorprendentemente natural, siendo capaz de descomponer escenarios extremadamente complejos en elementos de sentido común. Fuera de la demo, esto no es solo teoría. Jensen Huang anunció que el Mercedes CLA con la tecnología Alpamayo se lanzará oficialmente en EE. UU. en el primer trimestre de este año, y luego llegará a Europa y Asia. Este coche fue calificado por NCAP como el más seguro del mundo, gracias a la exclusiva arquitectura de “doble pila de seguridad” de NVIDIA. Cuando el modelo de IA de extremo a extremo no tiene suficiente confianza en la carretera, el sistema cambia inmediatamente al modo de seguridad tradicional y más seguro, asegurando protección total. Durante la presentación, Jensen Huang también mostró la estrategia de robótica de NVIDIA. Competencia entre nueve principales fabricantes de IA y hardware afines, todos expandiendo líneas de productos, especialmente en el ámbito de robótica; las celdas resaltadas corresponden a productos lanzados desde el año pasado Todos los robots estarán equipados con el miniordenador Jetson y serán entrenados en el simulador Isaac de la plataforma Omniverse. Además, NVIDIA está integrando esta tecnología en sistemas industriales como Synopsys, Cadence y Siemens. Jensen Huang invitó al escenario robots humanoides y cuadrúpedos como los de Boston Dynamics y Agility, enfatizando que el mayor robot es en realidad la propia fábrica De abajo hacia arriba, la visión de NVIDIA es que, en el futuro, el diseño de chips, de sistemas y la simulación de fábricas serán acelerados por la IA física de NVIDIA. Durante la presentación, los robots de Disney también hicieron una aparición especial, y Jensen Huang bromeó con estos adorables robots diciendo: “Serán diseñados en computadoras, fabricados en computadoras e incluso probados y verificados en computadoras antes de enfrentarse realmente a la gravedad”. Si no fuera Jensen Huang, cualquiera podría pensar que toda la keynote fue el lanzamiento de un fabricante de modelos. En una época donde el escepticismo sobre la “burbuja de IA” es alto y la Ley de Moore se desacelera, Jensen Huang parece necesitar demostrar con hechos lo que la IA puede lograr, para fortalecer la confianza de todos en ella. Además de presentar el nuevo y potente superordenador de IA Vera Rubin para calmar la demanda de cómputo, dedicó más esfuerzo que nunca en aplicaciones y software, tratando de mostrarnos a toda costa los cambios tangibles que la IA traerá. Como dijo Jensen Huang, antes hacían chips para el mundo virtual, ahora ellos mismos demuestran y centran su atención en la IA física representada por la conducción autónoma y robots humanoides, adentrándose en el competitivo mundo físico real. Al fin y al cabo, solo cuando la batalla comienza, el negocio de la “industria militar” puede prosperar. *Por último, aquí va el video sorpresa: Debido al tiempo limitado del discurso en el CES, Jensen Huang no pudo cubrir muchas diapositivas. Así que, en vez de eso, hizo un divertido corto con las diapositivas que no se mostraron. Disfruta⬇️ 0
0
Disclaimer: The content of this article solely reflects the author's opinion and does not represent the platform in any capacity. This article is not intended to serve as a reference for making investment decisions.
PoolX: Haz staking y gana nuevos tokens.
APR de hasta 12%. Gana más airdrop bloqueando más.
¡Bloquea ahora!
You may also like

DRIFT fluctúa un 40,2% en 24 horas: rebote desde el mínimo, el plan de recuperación sigue en marcha
Bitget Pulse•2026/05/25 09:31
Trending news
MoreCrypto prices
MoreBitcoin
BTC
$77,486.46
+0.79%
Ethereum
ETH
$2,114.91
-0.15%
Tether USDt
USDT
$0.9989
+0.01%
BNB
BNB
$661.31
+0.39%
XRP
XRP
$1.36
-0.38%
USDC
USDC
$0.9999
+0.01%
Solana
SOL
$85.91
-0.37%
TRON
TRX
$0.3663
+0.71%
Hyperliquid
HYPE
$63.51
+0.69%
Dogecoin
DOGE
$0.1028
-0.35%
Cómo vender PI
PI llega a Bitget: ¡Compra o vende PI rápidamente en Bitget!
Operar ahora
¿Aún no eres un Bitgetter?¡Un paquete de bienvenida de 6.200 USDT para los nuevos Bitgetters!
Regístrate ahora